
DeepMind SynthID is not a new keyboard for 80s music, it’s watermarking for GenAI content
Can you tell the difference between human-written and AI-generated text? Apart from the obvious old “delve” and beginning every article with the passive “In the age of…”, it’s not getting easier. Current “AI detectors” are about as much use as James McCormick’s garden-assembled ADE-651 bomb detector.
GenAI text detection might be a bit dodgy, but eliminating GenAI matters a lot — whether you agree or not — in some corners of our world, especially in education, software development, and web content creation. Only just recently, the BBC reported a cheating University student was caught cheating by their tutor using AI detection and faces an academic misconduct charge — what a terrible start to adult life.
Now the wonks at Google DeepMind have worked out how to inject watermarks into GenAI text, and it’s called SynthID.

Hidden signatures in GenAI text are coming soon
Think of it like this: just as photographers add invisible watermarks to protect their photos, GenAI companies can now add subtle “signatures” to text generated by their AI models. Unlike traditional watermarks that you can see, these signatures are invisible but mathematically detectable.
How does SynthID work?
Here’s how it works: When AI generates text, it chooses each word based on probability – like playing a very sophisticated word prediction game. The new watermarking technique slightly tweaks this process, creating a hidden pattern that can be verified later. It’s like the AI is leaving behind a trail of breadcrumbs that only special detection tools can find.
Haven’t we already solved this problem with “AI detectors”?
No, the online services you see are completely unreliable (educate me?). They probably always will be when using probabilities “after the fact” (after the words are written).
But the SynthID approach is different because it’s about injecting a watermark at the time the LLM creates the tokens and the text.
This approach offers several advantages over other methods of detecting AI text:
- It’s more reliable than trying to spot AI text after it’s written.
- Unlike other solutions, it doesn’t need to keep a database of all AI-generated content.
- It doesn’t noticeably change the quality of the AI’s writing.
- It’s computationally efficient, meaning it won’t slow down the AI.
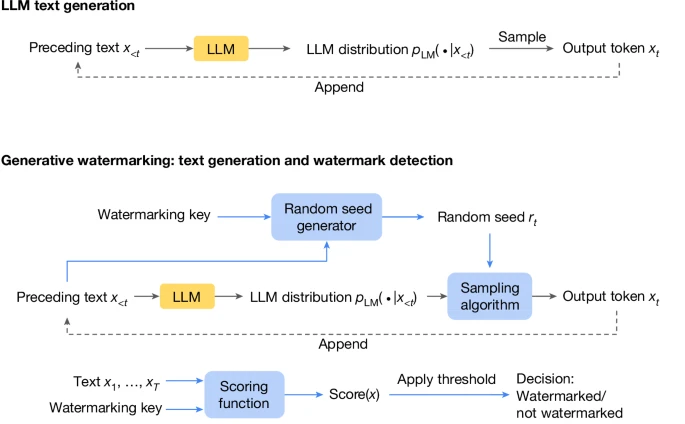
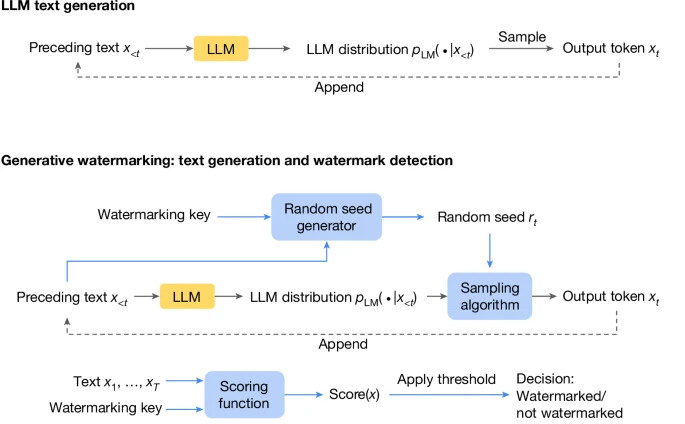
SynthID visualized
LLM text generation typically involves generating text from left to right by repeatedly sampling from the LLM distribution. Bottom: a generative watermarking scheme typically consists of the three components, in the blue boxes: random seed generator, sampling algorithm and scoring function. These can be used to provide a text generation method and a watermark detection method. In the SynthID-Text generative watermarking scheme, we use the Tournament sampling algorithm.
Can I circumvent SynthID?
In the Nature article, the authors disclose that if you edit the GenAI content, then it might break the watermarking.
For those of us that use GenAI to overcome procrastination and gestate ideas, but then do the last mile ourselves — including creating unique content based on a GenAI source — then you are likely to circumvent detection. But we aren’t trying to, because we’re ultimately the creator and not AI. So that’s probably correct.
What SynthID text watermarking means for creators
If you’re producing mass text output using a Google model — or any model in future if all LLM owners use the OSS version — then people will be able to find out if you’ve (a) used GenAI, and (b) should have used GenAI, and (c) disclosed whether you used GenAI.
What SynthID means for publishers
In a phrase, bugger all. Watermarks won’t help you track if someone’s GenAI text is based on your published content.
Maybe there’s a way to watermark published content (like a signature?) but whether that would “survive” being used as training data into the LLM… someone brighter than I might know the answer, but I doubt it. LLM training is not copying, if anything it’s a more destructive method than (a) GenAI text, (b) human edits.
LLMs consume published information like a black hole consumes information and radiates it out in a different format.
What do you think about watermarking? Ping us on social media and have your say!
Now go read the Nature article and tell me what it all means 😆